RichyHBM
Software engineer with a focus on game development and scalable backend development
From One to a Million - What is it to be Scalable?
The term scalability often gets thrown about when creating online services. Most people just assume it means having the ability to add additional servers on demand, and to an extent that is mostly what it is, but of course if you are in a situation in which you have the need to add more servers all you are doing is moving the bottleneck further up the line.
To be truly scalable the bottleneck needs to be removed, or at least mitigated as much as possible. Sometimes this can be as simple as adding a new layer between your API and the Datastore, minimizing the connections to a database for example. In other situations you may be able to move any processes offline, this also allows your frontline API to go down without any processes terminating.
A practical example
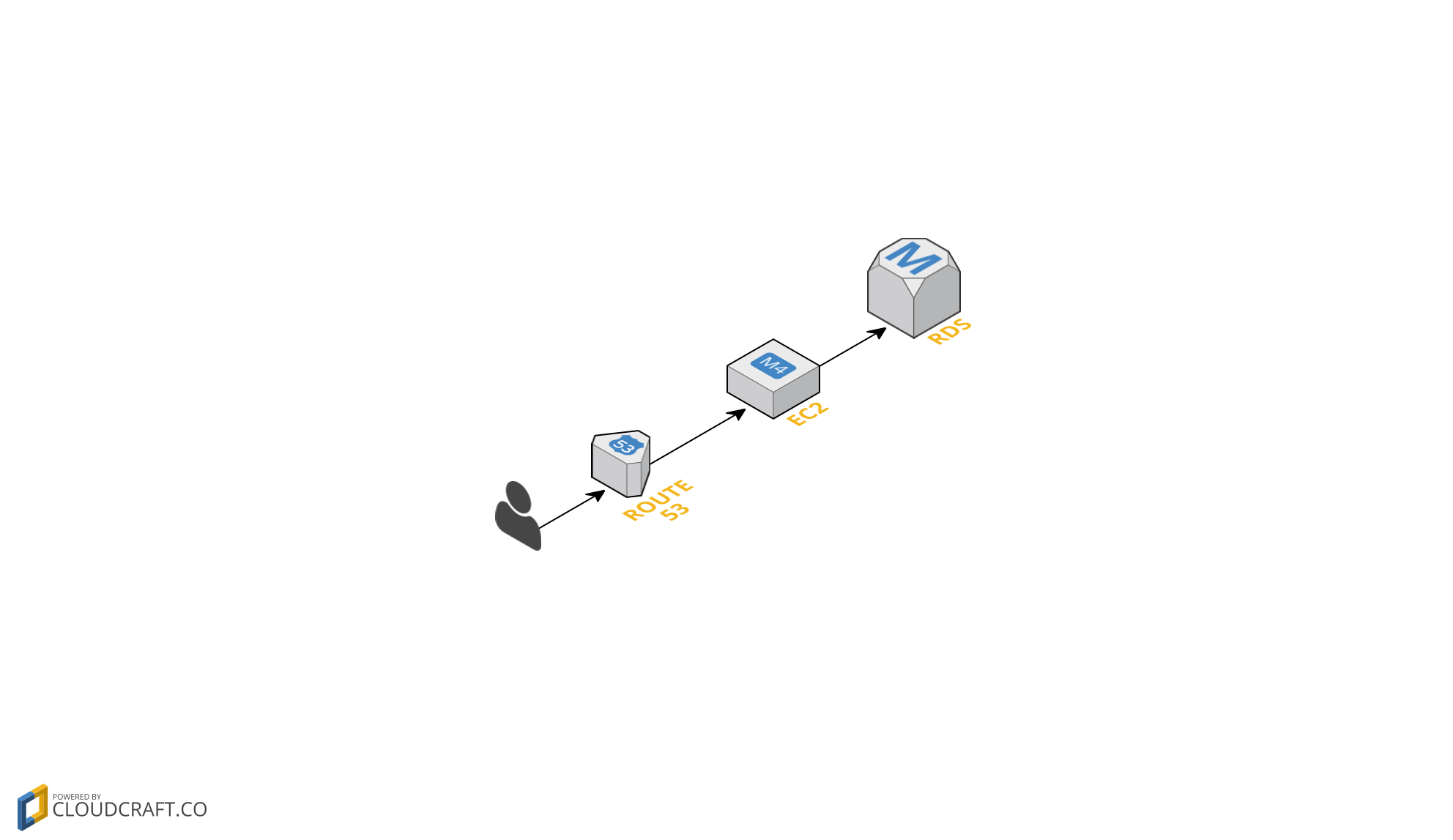
Let’s take one of the simplest examples, moving a website from a single machine into a web service capable of scaling to many users, in order to illustrate how “scalability” works.
In this example there is a simple a web server that talks to a database which you access via a domain address. As users hit the service it creates tasks for the server to perform; take an input, read the database, perform some computation, and return data back to the user… With a small number of users this is fine, the server will be able to handle all these tasks and will perform adequately, but as more users start to access the service the server will get closer and closer to reaching maximum capacity. Sooner or later the server will reach a point at which it can no longer take requests, be that because of computational performance, memory, threading issues, sockets…
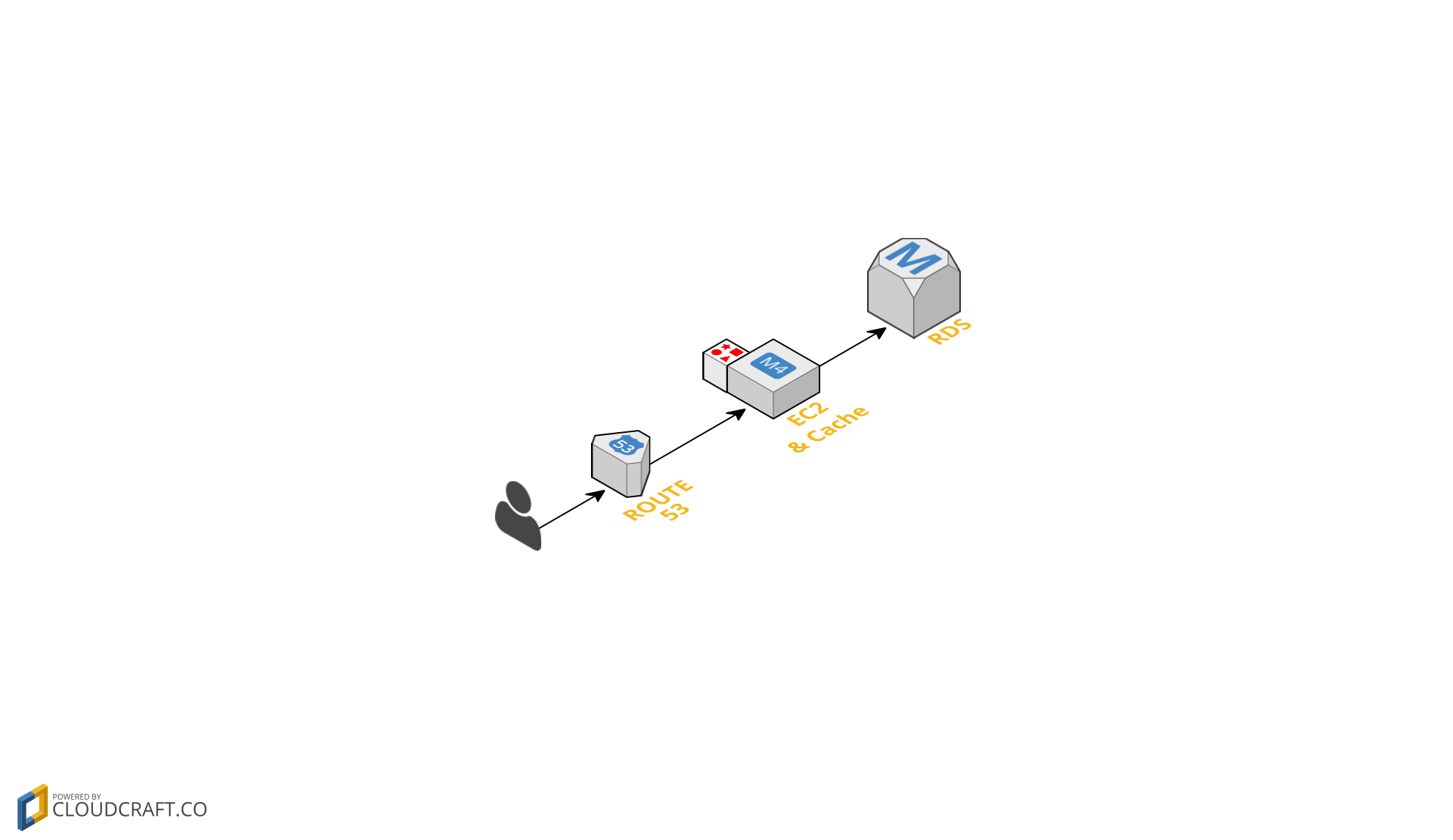
A quick gain here could be the introduction of a caching mechanism, this ensures that for requests taking the same input you can simply return a cached response and skip the computation. Of course this depends on the tasks to perform and if these are deterministic, i.e. if given the same input they return the same output.
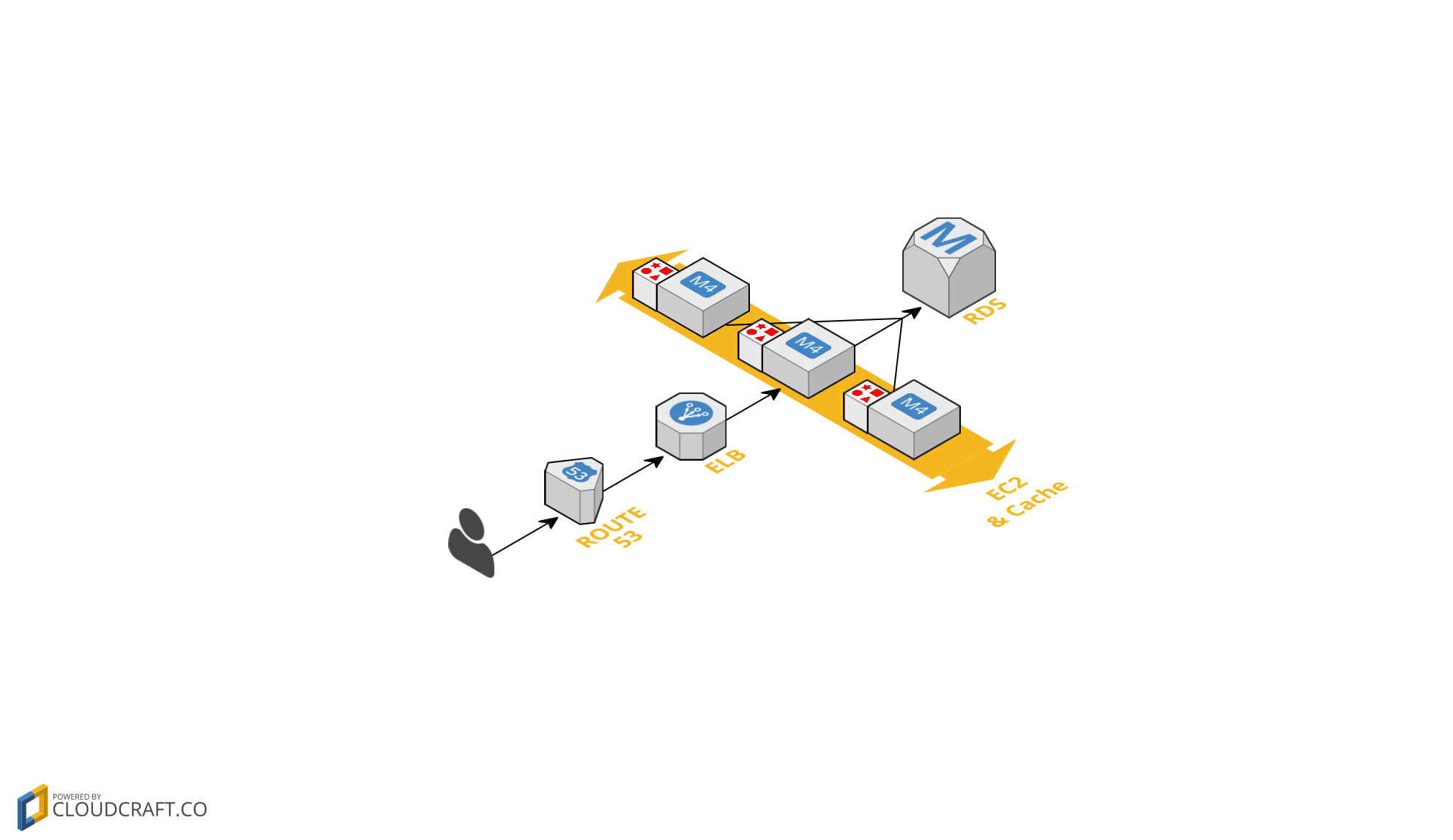
However sooner or later you will run into the same issues as before, it’s at this point you can start adding additional servers. Using functionality like auto-scaling allows the amount of servers to increase as the load or amount of users increases. This allows you to remove the limitations that a single server may have, cpu issues, memory issues… but still leaves you with design choices that may not be suited for scalable systems. As you add more servers to your system you are just passing the bottleneck up to the next component, which may or may not be able to make use of distributed workload.
It will get to a point where the design of your service will need to change in order to allow for efficient scalability, in the previous example it could be that the database reaches a point in which it can no longer handle any more connections (This would be very hard to reach, but the bottleneck is still potentially at that point). Instead you could take the approach of making any excessive computation a background process. For the example given, this could just be as easy as having the servers return a default response that can be cached; and put any new input onto a queue to be processed at a later time, this means that users will get their responses eventually rather than instantaneously but will allow for a much larger amount of users to make requests at a time.
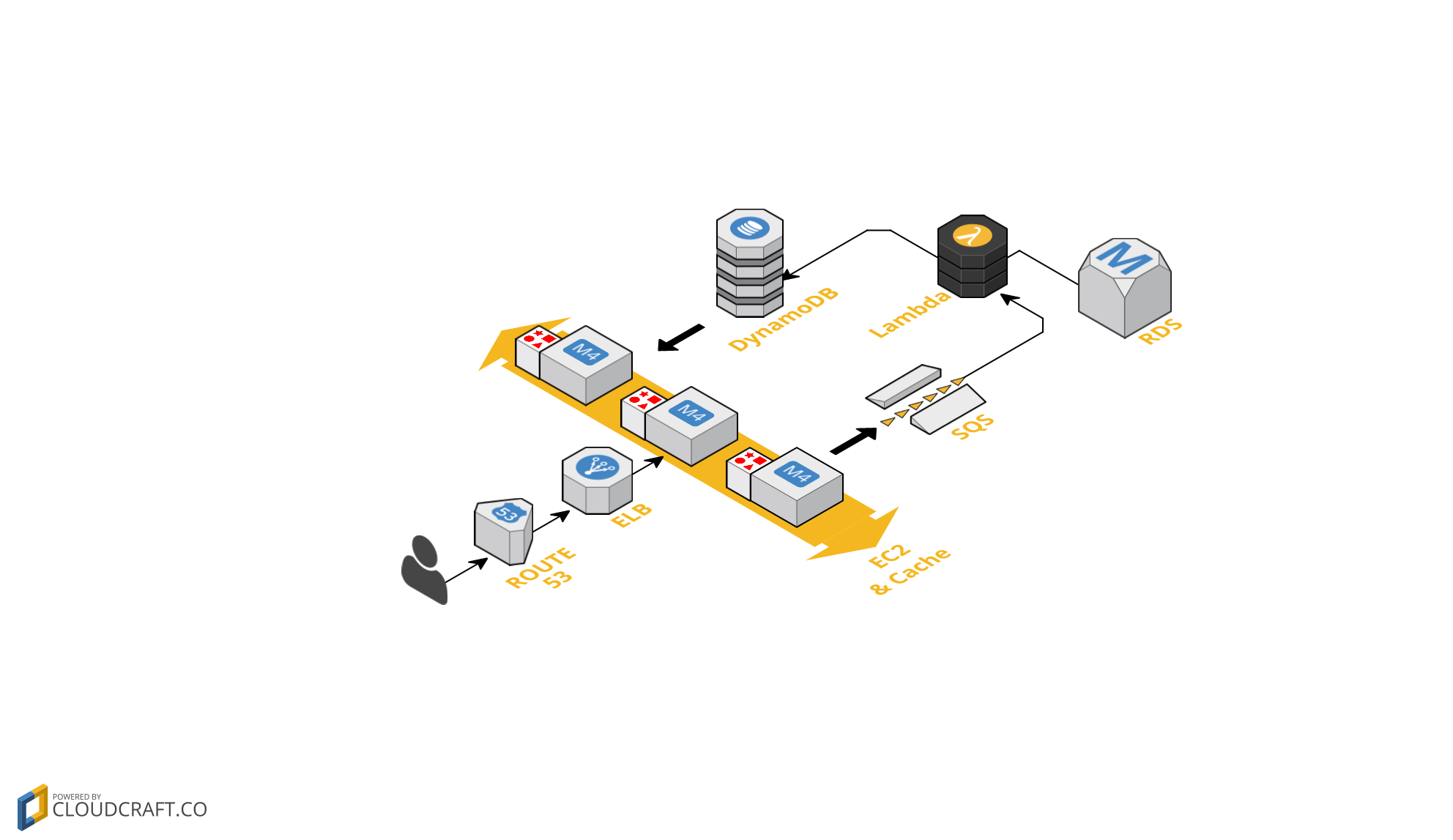
By doing all of this the original website has been converted from a service that could only handle a limited amount of users into a much more robust and scalable service, a service that could grow automatically as the amount of requests grow.